Fulltextové hledání - obecně
Fulltextové hledání je jednou z možností hledání v systému ABRA Gen ve většině číselníkových a dokladových agend, kde je k dispozici Panel fulltextového hledání.
Princip fulltextového hledání spočívá ve vytvoření množiny slov z vybraných položek požadované agendy. Tato slova se umístí do nové tabulky v databázi začínající prefixem FSU$.
Před zavedením podpory Unicode pro fulltextové hledání v systému ABRA Gen se pro tabulky (jejichž kódování bylo ANSI) používal název prefixu FS$. Po zavedení Unicode se tabulky nově vytvářejí s prefixem FSU$, díky čemuž je možné rozlišit tabulky se starým a novým kódováním mezi sebou. K tabulkám fulltextového hledání dříve vytvořeným v ANSI je možné dogenerovat tabulky s prefixem FSU$ v Unicode pomocí funkce Převést na unicode. Staré tabulky v ANSI s prefixem FS$ v systému zůstanou, ale budou již zbytečné, nebudou se používat. Tyto již zbytečné tabulky je možné následně odstranit pomocí funkce Aktualizovat fulltext.
Při založení nebo změně definice se slovům v tabulce musí ručně pomocí funkce Aktualizovat fulltext napočítat tzv. indexy, díky kterým je pak umožněno rychlé hledání. Po prvním ručním napočítání indexů dochází pak při každém uložení záznamu v patřičné agendě k indexaci záznamů automaticky.
Automatická indexace záznamů je z uživatelského pohledu výhodná (indexy jsou stále aktuální, uživatel má jistotu, že se při každém použití fulltextového hledání prohledávají aktuální data, ruční aktualizaci indexů stačí provádět při úpravách definic), nicméně nevhodně navržená (příliš extenzivní) definice indexů může způsobit výrazné zpomalení práce se systémem.
Typickým příkladem jsou editační položky typu poznámka. Ve většině případů je délka zadávaného textu ve formulářích omezena na 8192 znaků, ale v některých případech toto omezení neplatí a do položky je možné zadat téměř libovolně dlouhý text (příkladem je poznámka na skladové kartě). Pokud do výrazu v definici fulltextového hledání zahrnete takovou položku a následně do ní při editaci záznamu vložíte text v délce stovek tisíc znaků, uložení jediného záznamu může trvat v závislosti na konfiguraci i desítky minut.
Slova jsou při ukládání do tabulky převedena na velká písmena a při vyhledávání se hledaný textový řetězec taktéž převádí na velká písmena. Jejich velikost tudíž nehraje roli. Při ukládání se odstraňuje veškerá diakritika (např. "převodka" bude uloženo jako "PREVODKA" atp.) a při hledání slov ji tedy není třeba zadávat. Slovem se rozumí textový řetězec, jehož délku a hranice je možné uživatelsky ovlivnit v detailu definice hledání. V implicitním nastavení a při inteligentním dělení slov je jím nicméně míněn řetězec od 0 do 100 znaků, ze kterého se odstraní interpunkční znaménka a který zohledňuje (tj. nedělí) některé užívané řetězcové konvence (e-mailová adresa, internetová adresa, číslo dokladu).
Pro samotné vyhledávání podporuje systém ABRA Gen v současné době následující režim:
-
zjednodušené fulltextové hledání
Ve starších verzích systému ABRA Gen bylo používáno složitější fulltextové hledání s podporou logických operátorů.
Zjednodušené fulltextové hledání je výrazně rychlejší (pokud se nepoužívá hledání uprostřed slov) než dříve používané hledání s logickými operátory
Pro zjednodušené fulltextové hledání platí následující:
- Pokud je do výrazu zadáno více slov, vyhledají se pouze záznamy obsahující všechna hledaná slova (jako by byl mezi každou dvojicí slov použitý logický operátor AND).
- Není-li určeno jinak, vyhledávají se pouze záznamy obsahující slova, která začínají zadaným řetězcem.
- Uživatel nicméně může některá hledaná slova uvodit hvězdičkou a tím si vynutit hledání zadaného řetězce i uprostřed slov.
- Jednotlivá slova nebo části slov je možné oddělit operátorem OR, poté se vyhledají záznamy obsahující libovolné ze zadaných slov nebo fragmentů. Viz také popis použití operátoru OR v kapitole Panel pro fulltextové hledání.
Pokud se zadaný řetězec hledá jen na začátku slov, je nový způsob hledání výrazně rychlejší. Pokud se však zadaný řetězec hledá ve slovech uvozených hvězdičkou (tzn. také uprostřed slov), je hledání naopak pomalejší. Používání této varianty proto vždy důkladně zvažte.
Chcete-li vyhledat všechny záznamy, které v indexovaných položkách obsahují slova začínající řetězcem abc, do pole Fulltext zapíšete abc.
Chcete-li vyhledat všechny záznamy, které v indexovaných položkách obsahují řetězec abc kdekoliv, i uprostřed slov, do pole Fulltext zapíšete *abc.
Viz také popis položky Výraz v kapitole Panel fulltextového hledání.
Tento režim vyhledávání byl k dispozici do verze 19.0 včetně, níže uvedený popis uvádíme jen pro úplnost, z historických důvodů. V aktuální verzi byl nahrazen zjednodušeným fulltextovým hledáním popsaným výše.
Při vyhledávání v tomto režimu platí, že interně je zapnuta tzv. rozšířená syntaxe. Hledání však ruší nutnost (nikoli možnost, viz níže) hvězdičkové konvence a systém dohledá záznam při zadání jakéhokoli úseku slova uloženého v tabulce. Pokud je tedy v tabulce uloženo slovo firma, bude záznam s tímto slovem dohledán, když budou do výrazu pro hledání zadány řetězce fir, rm, irma či i atp.
U uvozovek platí, že vyhledávaný text uzavřený do uvozovek bude hledán přesně. Zároveň s uvozovkami (ale pouze s nimi!) je možné kombinovat i symbol hvězdičky:
| Hledaný řetězec | Výsledek |
|---|---|
| top ten | Hledá se "%top% AND "%ten%". Tedy např. aaatopaaa bbbtenbbb. |
| "top" "ten" | Hledá se "top" AND "ten". Tedy přesně top ten. |
| "top" ten | Hledá se "top" AND "%ten%". Tedy např. top bbbtenbbb. |
| "top*" ten | Hledá se "top%" AND "%ten%". Tedy např. topaaa bbbtenbbb. |
Znak % odpovídá v databázi znaku hvězdičky. AND je logický operátor pro "a zároveň".
Lze tedy také využívat logické operátory AND, OR a NOT, stejně jako v rozšířené syntaxi.
Co se týče znaků + a -, tak pokud je + a - uprostřed zadaného slova, zachová se. Pokud je na začátku, zachová se taky, ale ve smyslu speciálního znaku - tedy zahrnout nebo nezahrnout do hledání. Pokud chceme hledat slovo, které začíná na + nebo -, je třeba ho odsadit escape znakem, tedy \+slovo nebo \-slovo. Pozor však, jakým způsobem je prováděno ukládání fulltext výrazů - pokud je nastaveno Dělení slov jako Inteligentní anebo Vlastní tak se takové slovo nemusí uložit ve fulltextovém slovníku tak, jak se očekává. Operátory závorek není možné použít.
Aby bylo možné fulltextové hledání v dané agendě používat, je nutné mít pro tuto agendu vytvořenou definici fulltextového hledání. To je možné těmito způsoby:
- Pomocí Průvodce vytvořením definice fulltextového hledání přímo v dané agendě.
- Vytvořením definice v agendě Fulltextové hledání.
Při používání fulltextového hledání není nutné prohledávat všechny položky ve všech záznamech v dané agendě. Množinu prohledávaných dat je možné omezit dvěma základními způsoby:
- Omezení množiny prohledávaných záznamů - před zahájením hledání je možné zobrazený seznam omezit s využitím omezení nebo filtru a následně prohledávat pouze tuto omezenou podmnožinu. Více viz popis ovládacího prvku Vyhledávat ve zvolené skupině / filtru.
- Omezení množiny prohledávaných indexů - v rámci definice fulltextového hledání v určité agendě je možné vytvořit několik indexů nad různými položkami a následně jednotlivé indexy aktivovat nebo deaktivovat dle potřeby. Více viz popis ovládacího prvku Indexy.
Neúmyslná aplikace omezení je nejčastější způsob, proč fulltextové hledání nenalezne všechna požadovaná data.
Pro pochopení fungování fulltextového hledání nabízíme dva typové příklady:
V agendě Adresář firem mějme založené tři firmy s názvy AAA, XY a Česká automobilka a.s. V agendě Fulltextové hledání vytvořme nový záznam, navažme jej na agendu Adresář firem, pomocnou db. tabulku ponechme s názvem Firms (v databázi tak vznikne tabulka s názvem FSU$FIRMS). Dále založme tyto řádky: v položce název zadejme Název, v položce dělení nastavme Inteligentní, min. délku slova nastavme na 3, max. délku slova na 8, v položce výraz vyberme datovou položku Name (Název) a definici uložme. Následně vyvolejme nad uloženým záznamem funkci Aktualizovat fulltext.
Pokud se nyní přepneme do agendy Adresář firem a do výrazu v panelu fulltextového hledání zadáme XY a stisknutím enteru provedeme dotaz, tak systém nic nenajde, neboť jsme v definici omezili min. délku slova na 3 znaky. Stejně tak i při pokusu o hledání slova automobilka bude výpis prázdný, neboť maximální délka slova byla nastavena na 8 znaků (a v tabulce je tedy uloženo slovo automobi, neboť systém slova ořezává na zadaný počet znaků zleva). Úspěšné výsledky tedy získáme u řetězců AAA, česká či automobi.
Z toho vyplývá, že při určování minimální a maximální délky slov musíme dbát na to, aby se do tabulky dostaly skutečně všechny řetězce a tedy vymezené hranice nebyly příliš restriktivní. V našem případě by tedy ideální nastavení bylo minimální délka slova 2 (aby se do tabulky dostal i název firmy XY) a maximální délka slova nejméně 11 (aby se do tabulky dostalo celé slovo automobilka). Pokud se slova dělí, pak je obvykle maximální délka slova nastavena na nejdelší očekávatelné slovo, které se v poli vyskytne nebo bude vyskytovat. Je dobré počítat s určitými rezervami.
V agendě Faktury vydané mějme založené tři faktury s čísly dokladu FV-1/2011, FV-1/2012 a FV-2/2012. V agendě Fulltextové hledání vytvořme nový záznam navažme jej na agendu Faktury vydané, pomocnou db. tabulku ponechme s názvem IssuedInvoices (v databázi tak vznikne tabulka s názvem FSU$ISSUEDINVOICES). Dále založme jeden řádek takto: v položce název zadejme Číslo dokladu, v položce dělení nastavme Inteligentní, min. délku slova nastavme na 3, max. délku slova na 20, v položce výraz vyberme datovou položku Displayname (Číslo dokladu) a definici uložme. Následně vyvolejme nad uloženým záznamem funkci Aktualizovat fulltext.
Pokud se nyní přepneme do agendy Faktury vydané a do výrazu v panelu fulltextového hledání zadáme FV a stisknutím enteru provedeme dotaz, tak systém zobrazí všechny tři faktury. Pokud do výrazu zadáme *2012, tak systém zobrazí pouze faktury z roku 2012. Pokud zadáme FV-2/2012, tak systém zobrazí právě tuto fakturu. Inteligentní dělení v definici fulltextového hledání totiž za slovo považuje řetězce, které obsahují i znaky "-" a "/" a do databáze jsou tudíž uloženy v celku.
V agendě Skladové karty potřebujeme vyhledávat v kódu skladových karet například část kódu jako 11-04 nebo 18-30, nebo 20-48. Vytvoříme nový index fulltextového hledání pro skladové karty a hodnoty zadáme podle tabulky níže. Z tabulky je nejdůležitější sloupec Název a Výraz. Sloupec Popis, jen vysvětluje důvod nastavení a uvádí příklad.
| Typ | Název | Výraz | Popis | Dělení slov |
|---|---|---|---|---|
| QR výraz | Suffix Code, two char before - | IF (NxCharPosR('-', Code)=0, '', NxRight(Code, NxStrLen(Code) - NxCharPosR('-', Code) +1 +2)) | Vyhledávání dle části kódu začínající dva znaky před posledním výskytem znaku - Například kód karty. SJT00RT20-48SB(014) Vytvoří záznam do hledání: 20-48SB(014) Díky tomu lze vyhledat jen zadáním: 20-48 | Bílé znaky |
Tento příklad navazuje velmi úzce na předchozí příklad. Pro případy, kdy by bylo třeba hledat v textu ne před posledním výskytem znaku-, ale před předposledním stačí upravit výraz dle tabulky níže. Z tabulky je nejdůležitější sloupec Název a Výraz. Sloupec Popis, jen vysvětluje důvod nastavení a uvádí příklad.
| Typ | Název | Výraz | Popis | Dělení slov |
|---|---|---|---|---|
| QR výraz | Suffix Code, two char before second - | IF (NxCharPosR('-', Code)=0, '', IF (NxCharPosR('-', NxLeft(Code, NxCharPosR('-', Code))) = 0, '', NxRight(Code, NxStrLen(Code) - NxCharPosR('-', NxLeft(Code, NxCharPosR('-', Code)-1 )) +1 +2))) | Vyhledávání dle části kódu začínající dva znaky před předposledním výskytem znaku - Například kód karty. LJT06RT-09-98S(014) F472 Vytvoří záznam do hledání: RT-09-98S(014) F472. Díky tomu lze vyhledat jen zadáním: RT-09. | Bílé znaky |
Výraz uvedený výše v tabulce lze vložit v agendě Skladové karty do vlastního sloupce, kde je následně vidět, na jaká slova se kód rozdělí.
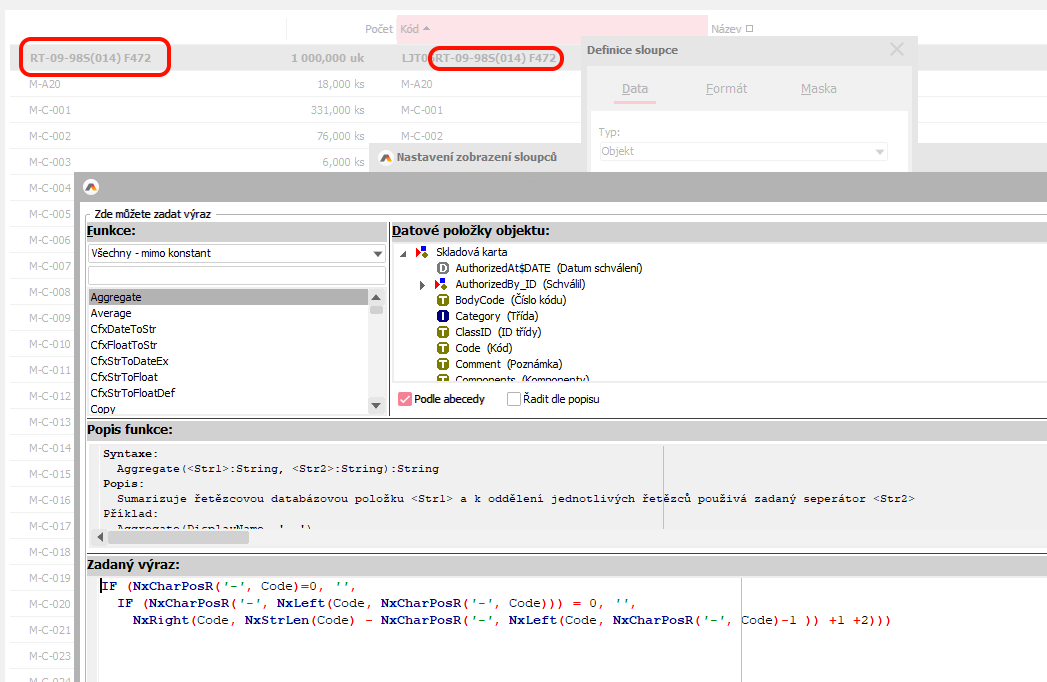
Výraz ve sloupci, který byl použit v rámci nastavení indexu fulltextového hledání zobrazí, na jaká slova se Kód rozdělí. Lze tak snadno zkontrolovat, zda výraz rozdělí text dle potřeby.
Podobně jako v předchozích příkladech budeme vyhledávat v číselníku skladových karet, tentokrát v poli Název. .Například část názvu jako 1900nd. Upravíme stávající index, který jsme vytvořili v předchozím příkladu pro pole Name. Hodnoty zadáme podle tabulky níže. Z tabulky je nejdůležitější sloupec Název a Výraz. Sloupec Popis, jen vysvětluje důvod nastavení a uvádí příklad.
| Typ | Název | Výraz | Popis | Dělení slov |
|---|---|---|---|---|
| QR výraz | Name without chars ( ) | NxSearchReplace(NxSearchReplace(Name, '(', ' ', 2), ')', ' ', 2) | Vyhledávání dle slov v názvu bez znaků () Například v názvu konektor socker, 18+3 dt. AWG20 (1900ND08S1A00A) Index vytvoří slova pro hledání: konektor socker, 18+3 dt. AWG20 1900ND08S1A00A Díky tomu lze vyhledat jen zadáním výrazu: 1900nd. | Bílé znaky |
Fulltextové hledání je také možné logovat zadáním patřičných sekcí do souboru Nexus.cfg do samostatného souboru a to přes třídu FastSearch. Například takto:
[Logs]
LogsDirectory=C:\Logs
[Log.FastSearch]
Enabled=1
Level=6Více viz kap. Logování běhu aplikace.