Kapitola popisuje možnosti generování tiskových sestav, exportů a B2B exportů prostřednictvím zasílání HTTP požadavků v rámci Web API.
V kapitole Další příklady použití Web API v ABRA Gen naleznete konkrétní příklad, jak prostřednictvím rozhraní Web API realizovat vygenerování tiskové sestavy objednávky přijaté a její uložení do PDF souboru. Možnosti Web API jsou však širší.
Základní principy:
- jsou podporovány standardní tisky, definovatelné exporty a B2B exporty
- nejsou podporovány Reporty prodeje a podobné agendy
- tisky i exporty je možné používat v rámci základního (GET) i rozšířeného (POST) dotazování
- tisknout i exportovat je možné do formátů PDF, XLSX a CSV
- formát se definuje prostřednictvím Content negotiation (HTTP hlavička Accept) nebo přímo v URL požadavku doplněním odpovídající přípony k názvu kolekce (pouze v základním dotazování)
- součástí zasílaného požadavku je ID tiskové sestavy, exportu nebo B2B exportu a seznam ID záznamů, které se mají vytisknout nebo vyexportovat
- k určení typu výstupu (tisk, definovatelný export nebo B2B export) slouží speciální query parametry
V tiskových sestavách je vždy zapotřebí nějakým způsobem specifikovat ID tištěného záznamu (nebo skupiny záznamů), ID tiskové sestavy a požadovaný výstupní formát.
Pro úspěšné generování tiskových sestav prostřednictvím Web API je zapotřebí spouštět službu Web API serveru pod uživatelem operačního systému s oprávněním k tisku na používané tiskárně.
Dostupné možnosti si ukážeme na příkladech.
HTTP požadavek (základní dotazování):
GET http://localhost:699/demodata/issuedinvoices/8M00000101?select=id&report=W400000001- demodata = alias spojení
- issuedinvoices = název kolekce (Faktury vydané)
- 8M00000101 = ID tištěného záznamu (konkrétní faktury vydané)
- W400000001 = ID použité tiskové sestavy (Formulář faktury vydané)
Pokud bychom serveru poslali uvedený požadavek bez dalšího upřesnění, nevytvořila by se žádná sestava, ale obdrželi bychom zpátky pouze ID záznamu (viz použití klauzule SELECT) ve formátu JSON. Přestože je specifikováno ID reportu, není určen formát. Query parametr report se v takovém případě ignoruje a požadavek je zpracován jako zcela běžný požadavek na získání dat.
Výsledek zpracování:
{"id":"8M00000101"}Formát můžeme určit dvěma způsoby:
- buď společně s požadavkem provést Content negotiation (odeslat HTTP hlavičku Accept)
- nebo formát zahrnout přímo do URL požadavku jako "příponu" názvu kolekce
Obě metody podporují trojici formátů - PDF, XLSX a CSV.
Společně s požadavkem odešleme HTTP hlavičku Accept, ve které v závislosti na požadovaném výstupním formátu uvedeme jeden ze tří dostupných typů:
Accept: application/pdfAccept: application/vnd.openxmlformats-officedocument.spreadsheetml.sheetAccept: text/csvMísto odesílání HTTP hlavičky je možné formát specifikovat přímo v URL požadavku, který bychom pro jednotlivé formáty upravili následovně:
GET http://localhost:699/demodata/issuedinvoices/8M00000101.pdf?select=id&report=W400000001GET http://localhost:699/demodata/issuedinvoices/8M00000101.xlsx?select=id&report=W400000001GET http://localhost:699/demodata/issuedinvoices/8M00000101.csv?select=id&report=W400000001Není-li uvedeno jinak, v příkladech v této kapitole předpokládáme používání Content negotiation, proto URL adresy specifikaci formátu neobsahují. Některý ze způsobů stanovení výstupního formátu je nicméně zapotřebí používat.
Pokud je v rámci Content negotiation požadován určitý formát a v URL požadavku je uveden jiný, formát specifikovaný v URL má přednost před hlavičkou, tj.
Accept: application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
...
GET http://localhost:699/demodata/issuedinvoices/8M00000101.pdf?select=id&report=W400000001způsobí vygenerování tiskové sestavy ve formátu PDF (hlavička s požadavkem na XLSX se ignoruje).
Používat klauzuli SELECT není povinné (pouze obecně doporučené, získávání celých objektů včetně nepotřebných polí je neefektivní). Je však nutné zajistit, aby odpověď vždy obsahovala pole s názvem ID, které slouží k výběru objektů pro tisk. Takže zatímco požadavek ve tvaru
GET http://localhost:699/demodata/issuedinvoices/8M00000101?report=W400000001tiskový výstup vytvoří, následující požadavek skončí chybou (400 Bad Request):
GET http://localhost:699/demodata/issuedinvoices/8M00000101?select=displayname&report=W400000001{"title":" Chybějící field \"ID\"","description":" V dotazu chybí field \"ID\", kterým jsou vybírány BO k exportu"}Stejnou chybou by požadavek skončil, kdybychom sice vybrali ID, ale přejmenovali ho prostřednictvím aliasu:
GET http://localhost:699/demodata/issuedinvoices/8M00000101?select=id+as+IDnumber&report=W400000001{"title":" Chybějící field \"ID\"","description":" V dotazu chybí field \"ID\", kterým jsou vybírány BO k exportu"}Uvedený příklad je jednou z možností, jak může požadavek vypadat. Ke stejnému výsledku nicméně povedou také následující varianty:
Základní dotazování nad kolekcí, s klauzulí WHERE:
GET http://localhost:699/demodata/issuedinvoices?select=id&where=id+eq+'8M00000101'&report=W400000001Rozšířené dotazování nad subresourcem kolekce BO:
POST http://localhost:699/demodata/issuedinvoices/query?report=W400000001Tělo požadavku:
{
"select": "id",
"where": "id='8M00000101'"
}Rozšířené dotazování nad obecným resourcem:
POST http://localhost:699/demodata/query?report=W400000001Tělo požadavku:
{
"class": "issuedinvoices",
"select": "id",
"where": "id='8M00000101'"
}Při používání rozšířeného dotazování je nutné požadovaný výstupní formát specifikovat v HTTP hlavičce, obdoba varianty "s příponou" ze základního dotazování zde k dispozici není.
Níže uvedená chyba znamená, že URL požadavku neobsahuje query parametr report (ani export, viz Generování definovatelných exportů a B2B exportů), přestože:
- v URL požadavku je formou přípony k názvu kolekce specifikován některý z podporovaných výstupních formátů (PDF, XLSX, CSV)
-
nebo byl požadavek odeslán s hlavičkou Accept, ve které byl specifikován některý z podporovaných výstupních formátů
- application/pdf
- application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
- text/csv
{
"title": " Chybějící parametry",
"description": " Není zadán parametr \"report\" ani \"export\""
} Pokud je zapotřebí vytisknout více záznamů než jeden, stačí odpovídajícím způsobem upravit klauzuli WHERE, aby při zpracování požadavku byla vybrána požadovaná skupina záznamů (v souladu s pravidly zápisu používanými v jednotlivých způsobech dotazování).
Základní dotazování - úprava URL:
GET http://localhost:699/demodata/issuedinvoices?select=id&where=id+in+('8M00000101','1O00000101')&report=W400000001Rozšířené dotazování - úprava těla POST požadavku:
{
"class": "issuedinvoices",
"select": "id",
"where": "id in ('8M00000101','1O00000101')"
}Výše uvedené příklady předpokládají, že známe ID tiskové sestavy, kterou chceme k tisku použít. Tento údaj můžeme zjistit několika způsoby - přímo v systému ABRA Gen nebo prostřednictvím jiných nástrojů.
Jedná se o nejjednodušší způsob, pokud máme k dispozici systém ABRA Gen a chceme uživateli umožnit z API vytisknout určitou konkrétní sestavu.
Na místě, kde se požadovaná tisková sestava nachází (typicky na záložce Seznam příslušné agendy), použijeme klávesovou zkratku ctrl+I, která ID tiskové sestavy, na které máme focus, uloží do schránky Windows, z které je pak možné ID vložit do API požadavku (například pomocí klávesové zkratky ctrl+V). Nebo je možné použít funkci Tisk: Po výběru požadované množiny záznamů k tisku se zobrazí výběrový číselník tiskových sestav přiřazených k programovému místu, které odpovídá dané agendě. Kliknutím na záhlaví sloupců pravým tlačítkem vyvoláme lokální menu, ze kterého vybereme nástroj Editor sloupců a následně funkcí Nový sloupec do seznamu doplníme sloupec ID jako jednu z položek business objektu Tisková sestava. Takto získané ID můžeme následně použít v požadavku API, jak je uvedeno v příkladech výše.
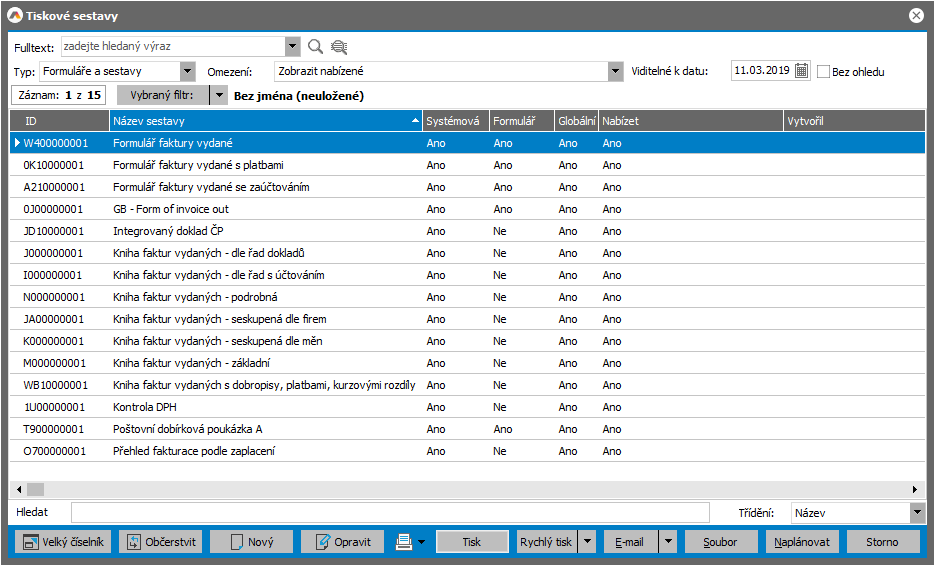
Systémová tisková sestava Formulář faktury vydané má ID W400000001.
Hledání podle názvu
ID tiskové sestavy můžeme získat přímo z Web API, pokud jej dokážeme dohledat podle nějakého identifikátoru. Pokud například víme, že hledáme sestavu týkající se dobropisů, můžeme zaslat požadavek
GET http://localhost:699/demodata/reports?select=id,displayname&where=title+like+'*dobropis*'a ve výsledku získat seznam ID všech tiskových sestav vyhovujících omezující podmínce.
Dotazování na řetězce a jejich části prostřednictvím Web API tímto způsobem zohledňuje velikost písmen (je case sensitive![]() Je-li nějaká položka case insensitive, znamená to, že není citlivá na velká a malá písmena, neboli nerozlišuje velká a malá písmena. Tzn., že není rozdíl, je-li napsáno např. "Abc" nebo "abc". Opak je case sensitive.). Pokud bychom ve výše uvedeném případě v klauzuli where použili řetězec *Dobropis* nebo *DOBROPIS*, nanalezli bychom pravděpodobně nic. Ve výrazu nicméně můžeme použít funkci upper() nebo lower(), které tento problém řeší:
Je-li nějaká položka case insensitive, znamená to, že není citlivá na velká a malá písmena, neboli nerozlišuje velká a malá písmena. Tzn., že není rozdíl, je-li napsáno např. "Abc" nebo "abc". Opak je case sensitive.). Pokud bychom ve výše uvedeném případě v klauzuli where použili řetězec *Dobropis* nebo *DOBROPIS*, nanalezli bychom pravděpodobně nic. Ve výrazu nicméně můžeme použít funkci upper() nebo lower(), které tento problém řeší:
GET http://localhost:699/demodata/reports?select=id,displayname&where=lower(title)+like+'*dobropis*'Při dotazování můžeme také zohlednit viditelnost (aktuálnost) tiskových sestav. Pokud bychom chtěli získat pouze sestavy viditelné k datu 12. 3. 2019, upravili bychom požadavek následovně:
GET http://localhost:699/demodata/reports?select=id,displayname&where=title+like+'*dobropis*'+and+(visibleto$date+eq+0+or+visibleto$date+ge+timestamp'2019-03-12')+and+(visiblefrom$date+eq+0+or+visiblefrom$date+le+timestamp'2019-03-12')Podmínka visibleto$date+eq+0 znamená "položka Viditelnost do není vyplněna". Způsob zápisu odpovídá způsobu uložení dat v databázi.
Hledání podle datového zdroje
Praktičtější může být hledání (příp. omezování výběru) tiskových sestav podle datového zdroje.
Tiskové sestavy se v systému ABRA Gen volají z různých míst, kterým říkáme programová místa, a ke každému takovému programovému místu může být přiřazen jeden nebo několik dynamických zdrojů dat (DynSQL). Jednou z vlastností každé tiskové sestavy je identifikace datového zdroje, ze kterého sestava čerpá data.
Identifikaci programových míst je možné nalézt v technické dokumentaci, konkrétně v popisu struktur a definic, ve kterém je pro každý modul uvedený Seznam programových bodů.
Programový bod (ProgPoint) a Programové místo jsou synonyma.
Pokud tedy potřebujeme získat seznam datových zdrojů používaných v sestavách faktur vydaných, vyhledáme ve zmíněném popisu struktur a definic programové místo (programový bod) Faktury vydané a zjistíme, že je k němu přiřazený jediný dynamický zdroj dat s ID 40SBPEINEFD13ACM03KIU0CLP4.
Seznam tiskových sestav využívajících tento zdroj dat pak získáme následujícím způsobem:
GET http://localhost:699/demodata/reports?select=id,displayname&where=datasource+eq+'40SBPEINEFD13ACM03KIU0CLP4'Díky této možnosti lze například uživateli aplikace využívající Web API nabídnout aktuální seznam dostupných sestav použitelných v daném kontextu, ze kterých si uživatel dle vlastních preferencí některou vybere a použije k tisku.
V popisu struktur a definic je možné nalézt pouze identifikátory systémových dynamických zdrojů dat přiřazených k systémovým programovým místům. Tato oblast systému je však uživatelsky modifikovatelná - je možné definovat vlastní dynamické zdroje dat, případně i vlastní programová místa nebo reportingové skupiny.
Typickým případem je situace, kdy systémový datový zdroj nenabízí určité informace, které v sestavě potřebujeme zobrazovat, proto si systémový datový zdroj zkopírujeme do uživatelského datového zdroje, rozšíříme dle potřeby, přidáme ke stejnému programovému místu, ke kterému je přiřazený původní systémový datový zdroj a nakonec vytvoříme tiskovou sestavu, ve které jako Zdroj dat nastavíme nově vytvořený datový zdroj.
Přidělené ID uživatelského zdroje zjistíme v nástroji DynSQLEditor, ve kterém se uživatelské datové zdroje definují - konkrétně na záložce Dynamické SQL pod seznamem Dynamické SQL příkazy pod označením ID příkazu (packed GUID).
Takto zjištěné ID datového zdroje můžeme následně použít k výběru tiskových sestav, které z příslušného zdroje čerpají data, stejně jako v případě systémových dynamických zdrojů dat, jejichž ID můžeme kromě DynSQLEditoru zjistit také v popisu struktur a definic.
Uvedený způsob můžeme alternativně použít ve všech případech místo hledání v popisu struktur a definic:
- v DynSQLEditoru použijeme funkci Importovat vše
- na záložce Místa v programu vyhledáme příslušné místo (v našem případě Faktury vydané)
- v panelu Seznam dynamických SQL je zobrazen seznam všech systémových i uživatelských dynamických zdrojů dat, které jsou k danému programovému místu přiřazeny
Pro generování definovatelných exportů a B2B exportů platí obdobné principy jako pro generování tiskových sestav. Rozdíly a rozšíření:
-
Místo query parametru report se používá query parametr export, ve kterém se specifikuje ID definovatelného exportu nebo B2B exportu.
GET http://localhost:699/demodata/workingrelations?select=id&where=id+eq+'5100000101'&export=I300000001 -
Pro B2B export je v URL zapotřebí použít další query parametr b2b, kterým se rozliší, zda se požadavek týká definovatelného exportu nebo B2B exportu.
- b2b=false - požadavek na vygenerování definovatelného exportu (výchozí hodnota)
- b2b=true - požadavek na vygenerování B2B exportu
GET http://localhost:699/demodata/issuedinvoices?select=id&where=id+eq+'8M00000101'&export=F000000001&b2b=true
Generování definovatelných exportů a B2B exportů je odvozeno od generování tiskových sestav a z tohoto důvodu je obdobně jako v případě tiskových sestav zapotřebí některým z uvedených dvou způsobů specifikovat výstupní formát.
Výstupní formát nemá v případě exportů věcný význam, neboť výsledkem zpracování požadavku jsou vždy strukturovaná data v podobě jednoznačně dané definicí exportu. Nicméně stejně jako v případě generování tiskových sestav, pokud se formát nespecifikuje, výsledkem zpracování HTTP požadavku jsou data ve formátu JSON (jako by se nejednalo o požadavek na export, ale standardní dotazování do dat). Z tohoto důvodu je zapotřebí i u exportů prostřednictvím Content negotiation nebo přípony u názvu kolekce v URL specifikovat některý z trojice formátů PDF, XLSX nebo CSV.
Následující požadavek
GET http://localhost:699/demodata/workingrelations.pdf?select=id&where=id+eq+'5100000101'&export=I300000001sice nevrátí PDF soubor, ale bez uvedení formátu (libovolného podporovaného formátu z uvedené trojice) se export nevygeneruje.