Definice definovatelných importů - záložka Detail
| Obsažené subzáložky: | Hlavička | Obsah | Formuláře |
|---|
Záložka zobrazí detailní informace k aktuální definici ze záložky Seznam. Položky jsou standardně rozděleny do subzáložek dle svého významu:
V horní části záložky Detail může být variantně zobrazen některý z Panelů definovatelných údajů detailu pro tuto agendu. Zobrazení panelu definovatelných údajů detailu závisí na aktuálním nastavení v menu Nastavení pro danou agendu a přihlášeného uživatele.
Tlačítko  v pravé horní části indikuje, že se jedná o variantní vstupní formulář.
v pravé horní části indikuje, že se jedná o variantní vstupní formulář.
Jedná se o definovatelné formuláře, tudíž jejich konkrétní vzhled v dané instalaci nemusí zcela přesně odpovídat stavu popsaném dále v tomto textu (zejména co se týče popisného pojmenování položek či jejich uspořádání v těchto formulářích). Proto je pro lepší identifikaci dále popsaných položek u většiny z nich uveden i její konkrétní název v databázi (italikou), viz identifikace popisovaných položek. Díky tomu si můžete definovat vlastní vzhled tohoto formuláře, tj. např. založit si a přidat si sem další položky, viz Přidávání dalších uživatelských položek, můžete si definovat i několik variant takového formuláře a třeba je i podmíněně přepínat, viz Tvorba dalších variant formuláře, přepínání variant. Nepotřebné položky si lze i skrýt, aby zbytečně na obrazovce nepřekážely. Viz Skrývání položek.
Popis položek var. formuláře v továrním nastavení:
| Název | Popis |
|---|---|
| Kód projektu Code |
Kód pro danou definici importu. Obecně může jít o libovolný alfanumerický řetězec 1-40 znaků dlouhý. Je to nepovinná položka, ale doporučujeme ji určitě využívat. Kód by měl být unikátní a co nejvýstižnější, aby usnadňoval pozdější orientaci v seznamech definic importů. |
| Název projektu Name |
Název pro danou definici importu. Obecně může jít o libovolný alfanumerický řetězec 1-160 znaků dlouhý. Je to nepovinná položka, ale doporučujeme ji určitě využívat. Název by měl být unikátní a co nejvýstižnější, aby usnadňoval pozdější orientaci v seznamech definic importů. |
| Zdroj dat ImportDataSource_ID |
Zdroj dat importu odkazující do číselníku Zdroje dat definovatelných importů. Povinný údaj. |
| Rozšiřující modul Extension |
Volba, zda se má pro zpracování použít rozšiřující nástavba definovatelného importu např. EDI. Výchozí hodnota: Žádný. |
| Pouze parsovat IsOnlyParse |
Informace, jestli se bude přímo zapisovat do business objektu (nezatrženo) nebo se jen provede parsování obsahu importního souboru a data se místo do business objektu uloží do dokladu dokumentů pro uživatelskou kontrolu (pole zatrženo) Výchozí hodnota: Ano (zatrženo). |
| Pouze ověřit IsOnlyValidate |
informace, jestli se bude pouze testovat správnost definice pro založení nebo aktualizaci business objektu (zatrženo). Při tomto nastavení se nevytváří žádný dokument ani se nezakládá/neaktualizuje business objekt. Výchozí hodnota: Ne (nezatrženo). |
| Typ transakce TransactionType |
V tuto chvíli nemá položka využití, je zde pouze připravena do budoucna. Bude možné zvolit, zda se bude import celého souboru zpracovávat v rámci jedné databázové transakce (hodnota: 0), po blocích dle nastaveného počtu záznamů (hodnota > 1) nebo bude transakce samostatná pro každý jednotlivý business objekt (hodnota: 1). Výchozí hodnota: 1 |
| Archivovat dokument IsDocumentArchive |
Volba, zda se bude obsah původního (neparsovaného) importního souboru archivovat jako příloha v novém dokladu dokumentu. Výchozí hodnota: Ne (nezatrženo). |
|
Procházet sekvenčně ProcessSequentially |
Pole určující, jestli se bude obsah importního souboru zpracovávat postupně tj. sekvenčně. Výchozí hodnota: Ano (zatrženo). Sekvenční zpracování dat - Data jsou v importním souboru vždy uvedena za sebou a všechny položky jsou pro každý hlavičkový business objekt uvedeny v jednom řádku. Nesekvenční zpracování dat - Data jsou v importním souboru uvedena napřeskáčku, tj. pořadí řádků v importních datech neodpovídá pořadí business objektů uvedených v importní definici. Pro nesekvenční import dat není možné mít v importních datech uvedeno více záznamů dané hlavičky |
|
Řádky pro přeskočení SkipLeadingRows |
Volba má význam pro textový soubor. Určuje počet řádků, které se na začátku zpracování souboru přeskočí. Typicky se jedná o hlavičku sloupců. Výchozí hodnota: 0 (žádné řádky se nepřeskakují). |
|
ImportType |
Informace, jakého typu je importní soubor. Povinná položka. Typ importu TXT: Jedná se o import dat v textovém formátu. Položky pro import se v importních datech definují pozicí a délkou. Typ importu CSV: Jedná se o import dat v textovém formátu. Položky pro import se v importních datech definují oddělovačem a pořadím položky v rámci jednoho řádku. Pro správné importování diakritiky při použitém kódování UTF 8 je potřeba využít volbu UTF 8 s BOM. Typ importu XML: Jedná se o import dat v XML strukturovaném formátu. Položky pro import se v importních datech definují pomocí XML větví. Typ importu Excel: Jedná se o import dat z tabulky MS Excel. Položky pro import se v importních datech definují pomocí názvu sloupce v Excelu a názvu záložky. Podporován je formát XLS i XLSX. Načítání dat z MS Excel probíhá pomocí OLE MS Excelu. Proto je nutné mít na počítači, kde import probíhá, MS Excel fyzicky nainstalován. Vlastní zpracování importu pak probíhá jako pro typ importu CSV. Je tedy podporováno a většinou i přímo vyžadováno používání masek řádků pro rozlišení typů importovaných objektů. Kromě oficiálně podporovaných formátu XLS a XLSX funguje import i z formátů jiných tabulkových kalkulátorů, např. Open Office (formát ODT). Přesto je ale nutné mít na počítači MS Excel nainstalován, jelikož, jak je již výše zmíněno, načítání dat z MS Excel probíhá pomocí OLE MS Excelu. |
|
Výchozí oddělovač CSV CSV_DefaultSeparator |
Znak oddělení položek CSV, použije se pro předvyplnění obdobné položky na položkách definice importu. Položka je pro typ importu CSV povinná. |
|
Znak ohraničující CSV text CSV_QuoteChar |
Ohraničení textu CSV v importních datech. Jde především o situaci ,kdy je potřeba mít uvnitř položky středník (znak uvedený jako oddělovač), ale nejedná se o oddělovač. |
|
CSV znaky konce řádku XLS_LineBreak |
Znaky odřádkování. Výběr z přednastavených voleb odřádkování typického pro platformy Windows, Mac a Unix. |
|
Způsob čtení dat z Excelu XLS_ReadValueType |
Položka je k dispozici jen v případě, že je zvolen Typ importu Excel. Volba určuje způsob přebírání dat z Excelu. Skutečná hodnota - Data se budou přebírat bez ohledu na jejich formátování v MS Excel. Zformátovaná hodnota - Data budou přebírat včetně použitého formátování v MS Excel. |
|
LogLevel |
Volba ovlivňuje, které logované informace z procesu zpracování definovatelných importů budou do logu zapisovány. Podrobná - Zobrazují se všechny logy kromě zobrazení naparsované struktury importního XML při XML importu. Výchozí hodnota Jen chyby - Zobrazují se jen chyby, pokud nějaké při importu a parsování vzniknou. (Log vznikne i v případě, kdy při importu žádná chyba nenastane.). Podrobná s rozšířením pro XML - Zobrazují se všechny logy včetně zobrazení naparsované struktury importního XML při XML importu. |
|
Prázdná importní data jsou chyba LIsEmptyDataError |
Pokud je položka nastavena na hodnotu ANO, přistupuje se při zpracování definovatelného importu k prázdným importním datům jako k chybě. Prázdný soubor je označen jako chybný a přesune se do adresáře pro chyby, pokud je adresář pro chyby zadaný. Nevznikne interní XML, a při nastavení volby Pouze parsovat nevznikne ani dokument s interním XML. Pokud je položka nastavena na hodnotu NE, pracuje systém se souborem jako by nebyl prázdný. Prázdný soubor se import pokusí zpracovat a vznikne tedy v tomto případě prázdné interní XML, tedy vznikne i dokument pro volbu Pouze parsovat. Soubor se přesune do archivního adresáře, pokud je adresář zadaný. Výchozí hodnota Ne. |
|
Logovat záznamy vzniklé zpracováním definovatelného importu CanLogBOCreatedByDefImport |
Pole má význam při samotném zpracování parsovaného souboru a ukládání Business objektu. Je-li položka zatržena, začnou se plnit řádky v agendě Logy, subzáložka Řádky def. importu.V řádcích se lze snadněji orientovat, než ve standardním logování v subzáložce Poznámka. Položku má smysl mít aktivní (zatrženou) v případě, kdy logy obsahují často chyby a je třeba dohledávat jejich příčinu. V případě, kdy je na hlavičce def. importu zatržena volba Pouze parsovat, tak se do subbzáložky Řádky def. importu nic nezapíše. Zápis proběhne až při zpracování rozparsovaného souboru v agendě Dokumenty. |
|
Ukládat obsah chybných záznamů CanLogContentsOfFaultyBO |
Zatržením toho pole se v případě chyby začne obsah Business objektu, dále jen BO, který se nepodařilo naimportovat (uložit) vypisovat do subzáložky Řádky def. importu v agendě Logy, položka Obsah neuloženého BO. Z tohoto obsahu je možné často snadněji identifikovat možnou příčinu neuložení BO. |
|
Ukládat skutečná importní data jako přílohy logu CanLogRawInputData |
V případě, kdy je položka zatržena se do agendy Logy, záložka Přílohy vytvoří dokument, jehož obsahem jsou skutečná importní data. Skutečnými importními daty se rozumí data po jejich případně transformaci, například pomocí skriptingu (háček “IEImportExport_AfterSetImportDocument_Hook”) nebo pomocí rozšiřujícího modulu definovatelných importů (EDI). Importní data se ukládají do obsahu samostatného dokumentu. Kategorie a další nastavení je stejné jako u dokumentů definovatelných importů vznikajících při volbě Pouze parsovat. Tedy kategorie IMP. Dokumenty nelze zpracovat a mají jiný prefix popisu. Pro kategorii je nutné mít přiřazenou řadu (stejně jako u EDI apod.). Dokument se skutečnými importními daty se automaticky připojí k záznamu logování jako příloha. V případě více záznamů logů se každý dokument připojuje pouze jednou. V dokumentu připojeného v záložce Přílohyje dostupná položka Název souboru. Ta se v případě importu jednoho souboru přejmenuje dle automaqticky generováného názvu (kombinace znaků a čísel). V případě importu více souborů současně, odpovídají názvy souborů reálným názvům importovaných souborů. |
|
Poznámka Note |
Zde je možno vepsat poznámku vztahující se k definicím definovatelných importů. |
Subzáložka Obsah slouží k zadání řádků dokladu. Obsahuje:
Jedná se o prvek editovatelný seznam, v němž je zobrazen seznam dosud zadaných řádků (na počátku prázdný). V definovatelných importech nelze obecně volit z různých typů řádků, jako tomu je např. u vlastní faktury. Seznam řádků se dělí na horní a spodní.
Horní seznam - je určen pro zadání tříd business objektů.
Spodní seznam - je určen pro zadání položek subkolekce třídy business objektu zadaného v nadřízeném seznamu.
Položky zadávané v řádcích horního seznamu tohoto dokladu:
| Název | Popis | |
|---|---|---|
| Třída objektu | Interní jednoznačná identifikace business objektu. Lze zadat výběrem z nabízených možností, nebo se automaticky vyplní po zadání položky CLSID. | |
| BO název třídy | Interní název BO (např.TNxReceivedOrder - Objednávka přijatá). Položka jen ke čtení, předvyplní se po zadání CLSID nebo Třídy objektu. | |
| CLSID | Interní jednoznačná identifikace business objektu (BO). Lze zadat ručně, nebo se automaticky vyplní po zadání položky: Třída objektu. Povinná položka | |
| Nadřízený | Odkaz na nadřízený business objekt (BO). Povinná jen u kolekcí BO. | |
| Typ importu |
Určuje způsob práce s business objekty (platí pro hlavičky i položky kolekcí), tj. jestli se bude vytvářet nový BO (nový záznam) nebo půjde o opravu již existujícího BO (opravu existujícího záznamu). Podporované volby: Nový: Vždy se zakládá nový BO (nový záznam). Oprava: Vždy se provádí oprava BO (oprava existujícího záznamu). Pokud se ID pro opravu nedohledá, záznam se nezpracuje. Oprava nebo Nový: Pokud se dohledá ID pro opravu BO (existujícího záznamu), provede se oprava. V opačném případě se založí nový BO (nový záznam). Výchozí hodnota: Nový |
|
| XML s atributy |
Položka je přístupná jen pro typ importu XML. Pokud je položka zatržena, je možné importovat i XML, které obsahuje atributy. Importní definice pro XML elementy i atributy je prakticky shodná. Výchozí hodnota: Neaktivní (nezatrženo). |
|
| Aktivní |
Příznak, jestli se bude daný BO při importu zpracovávat. Pokud je nastaveno na Ne, pak se nastavení v podřízené subkolekci ignoruje (bez ohledu na nastavení subkolekce), tj. daný BO se importem nezpracuje. |
|
| Provádět předvyplnění |
Položka je ve výchozím stavu nastavena na hodnotu Ano. V závislosti na nastavení položky se na nových business objektech vznikajících zpracováním def. importu provádí předvyplnění (metoda prefill) nebo se tato metoda neprovádí. (pokud je nastaveno na Ne). Možnost vypnutí předvyplňování je zde především z důvodu možnosti zakládat skladové karty v jednom jediném kroku. Vypnutí prefillu u jiných situací nedoporučujeme. Importy budou vyžadovat doplnit všechny potřebné položky, které jsou povinné pro založení BO - někdy až na takové úrovni, kterou zvládne pouze uživatel, který vidí do kódu systému. |
|
| Název záložky Excelu |
Položka je přístupná jen pro typ importu Excel. Položka určuje, ze které záložky Excelu budou hodnoty z Excelu pro daný objekt načítány. Je podporováno načítání hodnot pro více BO ze stejných nebo i různých záložek Excelu. Vyplnění položky je kontrolováno měkkou validací. Pro spuštění importu je vyplnění položky povinné. |
|
V zobrazeném seznamu položek ve spodním seznamu je možno zobrazit všechny záznamy nebo si jejich zobrazení omezit. K tomu slouží položka Omezení řádku v horní části spodního seznamu. Pokud zvolíte hodnotu Vše, pak uvidíte seznam všech položek, nehledě na to, jakou mají nastavenou hodnotu v položce Aktivní. Pokud budete chtít zobrazený seznam omezit pouze za položky Aktivní či Neaktivní, vyberete požadovanou možnost ze skrytého seznamu v této položce:
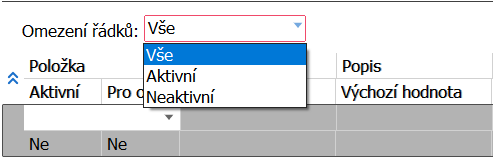
Příklad možnosti omezení zobrazených položek
Položky zadávané v řádcích spodního seznamu tohoto dokladu:
Kolekce je řazená a zpracovává se v nastaveném pořadí.
Seznam položek se aktualizuje při změně aktivního řádku v nadřízeném seznamu (viz horní seznam pro zadání tříd business objektů).
| Název | Popis | |
|---|---|---|
| Položka | Název položky business objektu (BO) v ABRA Gen (např. Firma). | |
| Jméno |
Interní název položky BO v ABRA Gen (např. Firm_ID). Povinné pole, pokud je položka Pro opravu nastavena na hodnotu Ne. Vyplní se automaticky výběrem pole Položka nebo ji lze zadat ručně. Položku lze využít pro definování proměnné nastavením prefixu *VAR* (vysvětlení dále v textu). K položkám vlastněné kolekce (Vlastněná kolekce je v GenDoc.chm definována textem (Owned), například: ResidenceAddress_ID(Owned)) se v definovatelných importech přistupuje jednoduše rozvinutím položky hlavního objektu pomocí názvu vlastněné kolekce a za tečkou přímo název položky vlastněné kolekce. Například takto: ResidenceAddress_ID.Street. |
|
| Popis | Libovolný popis nebo poznámka uživatele. Položka se předvyplní popisem z vybraného BO. | |
| Typ dat |
Datový typ položky. K dispozici jsou tyto datové typy: Řetězec, Celé číslo, Desetinné číslo, Kolekce, Datum, Ano/Ne, XML kolekce, Neurčeno, Jedinečná přípona proměnné, Excel propojení, Podmínka Pokud je nastaven datový typ Ano/Ne, pak zadaná položka musí nabývat hodnoty A nebo N. |
|
| Výraz |
Výraz, který se vyhodnotí nad daným BO a hodnotou získanou z importního souboru. Ve výrazu lze využívat proměnné (viz níže). Nelze zadat zároveň Výraz i SQL tj. nelze vyhodnocovat oba výrazy společně, vždy jen jeden z nich. Výraz můžete zapsat ručně nebo jej můžete sestavit komfortněji pomocí Editoru výrazů, který si můžete vyvolat po stisku funkčního tlačítka Pokud použijete ve výrazu konstantu "%s" pro získání hodnoty z datového zdroje více než jednou, musí být použita indexace. To znamená, že místo "%s" je potřeba použít např "%0:s" |
|
| SQL |
SQL výraz, který se vyhodnotí pro hodnotu získanou z importního souboru. Ve výrazu lze využívat proměnné (viz níže). Nelze zadat zároveň Výraz i SQL tj. nelze vyhodnocovat oba výrazy společně, vždy jen jeden z nich. Výraz SQL můžete zapsat ručně nebo jej můžete sestavit komfortněji pomocí Editoru výrazů, který si můžete vyvolat po stisku funkčního tlačítka Pokud použijete ve výrazu konstantu "%s" pro získání hodnoty z datového zdroje více než jednou, musí být použita indexace. To znamená že místo "%s" je potřeba použít např "%0:s". |
|
| Podmínka položky |
Podmínka, která se vyhodnotí pro hodnotu získanou z importního souboru. V podmínce lze využívat proměnné (viz níže). Výraz pro podmínku můžete zapsat ručně nebo jej můžete sestavit komfortněji pomocí Editoru výrazů , který si můžete vyvolat po stisku funkčního tlačítka |
|
| Vyhodnotit podmínku před zpracováním |
Při nastavené hodnotě NE se podmínka z pole Podmínka položky vyhodnocuje na již zpracované hodnotě z importních dat. Zpracováním se rozumí, že je provedena na hodnotě příslušná datová konverze a vyhodnoceny výrazy nebo SQL dotazy. Při hodnotě ANO se podmínka z pole Podmínka položky vyhodnocuje na tzv “syrové” hodnotě z importních dat. To znamená dříve než je na hodnotě provedena příslušná datová konverze a před vyhodnocením výrazu nebo SQL dotazu. Výchozí hodnota: Ne Mějme nadefinovaný základní import skladových karet v CSV formátu. Chceme v tomto importu kromě Kódu a Názvu skladové karty importovat také položku Procento obvyklé marže. Ta by měla být ve formátu desetinného čísla. Avšak v importním souboru zjistíme, že na dané pozici nejsou vždy jen čísla, ale třeba i text. Bez vyhodnocení podmínky před zpracováním by nám takový import skončil chybou v místě, kde by se místo čísla nacházel text. Díky tomu, že použijeme podmínku, například CfxStrToFloatDef('%s', -1, ',') <> -1, a nastavení Vyhodnotit podmínku před zpracováním na hodnotu Ano, jsou zpracovány jen ty záznamy, které budou podmínkou vyhodnoceny jinak, než -1. U záznamů, které podmínce nevyhoví, nedojde k importu této položky. Tzn. záznam se naimportuje, ale položka Procento obvyklé marže bude prázdná (nulová). |
|
| Aktivní |
Příznak, jestli se bude daná položka subkolekce zpracovávat (hodnota: Ano) nebo ignorovat (hodnota: Ne). Nastavení hodnoty je platné pro ověření, parsování, tvorbu BO. Po nastavení hodnoty Ano či Ne se tato hodnota přebere pro další přidanou položku BO. Výchozí hodnota: Ano |
|
| Pro opravu |
Využití jen u typu importů: Oprava nebo Oprava nebo Nový. Při nastavení na hodnotu Ano se vyhodnocením výrazu na řádku získá ID pro opravu. Výchozí hodnota: Ne |
|
| Formát | Speciální formátování pro typ položky, kde to má smysl (např. DateTime, Float ad.). Například formát datumu (YYYYMMDD), oddělovač desetinných čísel (tečka nebo čárka) atd. | |
| Výchozí hodnota |
Výchozí hodnota, která se použije v případě, že se hodnotu nepodařilo z importního souboru získat. Výchozí hodnotu lze také nastavit pro ty případy, kdy nechcete, aby se hodnota čerpala z importního souboru, ale potřebujete ji zadat přímo. Takovým příkladem může být ID střediska, kód skladu, ID skladu, firma atd. Položku lze využít pro získání hodnoty z proměnné definované prefixem *VAR*. |
|
 (může se lišit dle verze a
(může se lišit dle verze a Položky nastavení pro párování na importní soubor:
Vyplnění položek je povinné v závislosti na nastaveném typu importního souboru na hlavičce definice.
| Název | Popis | |
|---|---|---|
| Maska řádku |
Maska, jejímž vyhodnocením bude rozhodnutí, zda daný importní řádek zpracovávat či nikoliv (využití u TXT, CSV). Jinými slovy, pokud je na položce v Definici pro import maska zadaná, musí v importních datech řádek začínat znaky uvedenými v masce, jinak se nezpracuje. Zadávat lze na jedné položce pouze jednu masku. Pokud bychom zadali dvě masky oddělené středníkem, zpracovala by se jen ta data, která odpovídají celé masce včetně středníku. Maska rozlišuje velká a malá písmena (je key sensitive). Použití masky si vysvětíme na příkladu níže. Zadaná maska na položce BO objektu se automaticky kopíruje i na další přidávanou položku BO. Typickým příkladem využití je import dokladů, např. objednávek přijatých, kdy v importním souboru bude hlavička dokladu označena jako Header a řádky budou mít označení Rows, viz obrázek.
Následně je třeba nastavit stejnojmennou masku v ABRA Gen, aby systém rozpoznal, co je v importu Hlavička a co Řádky, a data zpracoval, viz obrázek.
|
|
| Sloupec Excelu |
Položka je přístupná jen pro typ importu Excel. Určuje, ze kterého sloupce se daná položka bude z MS Excelu načítat. Hodnota sloupce musí být vždy velkými písmeny, při zadání malého písmena se provede automatická konverze na velké písmeno. Písmena se zadávají bez apostrofů. |
|
| Způsob aktualizace textové položky |
Položka je k dispozici pro typy importů “Oprava” nebo “Oprava nebo nový” a pro řetězcové položky. V ostatních případech je položka nedostupná. Podle typu nastavení položky se při opravě řetězcové položky BO zapsání hodnoty chová takto: Přepsat - Původní hodnota se vždy přepíše řetězcem z importu. Výchozí hodnota. Přidat na začátek - Hodnota z importu se přidá na začátek k již existujícímu řetězci. Přidat na konec - Hodnota z importu se přidá na konec k již existujícímu řetězci. Zvolená varianta u jedné položky BO se automaticky přebere do dalších přidávaných položek BO. |
|
| Ořezávat mezery |
Pokud je položka nastavena na Ano, ořezávají se při parsingu automaticky koncové mezery zleva i zprava. Pokud je položka nastavena na Ne, pak se mezery neořezávají. Na hodnotu položky se bere ohled pro typy importu TXT, CSV, Excel. Pro typ XML se vždy importuje bez ořezání mezer. Výchozí hodnota je Ano. |
|
| Pozice |
Celé číslo, pozice začátku položky na řádku importního souboru. Pole dostupná jen pro Typ importu: TXT, CSV. |
|
| Délka | Celé číslo, délka položky. Pole dostupné jen pro Typ importu: TXT. | |
| Oddělovač | Oddělovač položek v textovém formátu CSV. Pole dostupné jen pro Typ importu: CSV. | |
| XML položka |
Jednoznačný název položky v importním XML souboru. Pole dostupné jen pro Typ importu: XML Pokud není pole vyplněno nebo není vyplněno pole Výchozí hodnota, nedojde ke zpracování pole při importu. Na toto je uživatel upozorněn zprávou při uložení definice. |
|
| XML větev |
Název větve položek kolekce v importním XML souboru. Položka dostupná jen pro Typ importu: XML. Povinná položka, bez které není možné uložit definici. |
|
| Operátor kombinace podmínek |
Nabízí hodnoty AND a OR. Výchozí AND. Používá se pro logické spojení více než jedné podmínky aktuálního business objektu. Položka je aktivní jen v případě, kdy v Typu dat je vybrána možnost: Podmínka.Dále je nutné mít vyplněnu položku Výraz. Více informací k této položce viz níže |
|
| Zastavit zpracování po nesplněné podmínce |
Nabízí hodnoty Ano a Ne. Výchozí Ne. Pokud je aktuální stav vyhodnocení všech podmínek daného Business objektu, dále jen BO "NE" a položka je nastavena, ukončí se proces parsování všech následujících položek daného i podřízených BO. Při správném použití lze takto urychlit zpracování, typicky u položek, které jsou dále při nesplněné podmínce již zbytečné. Položka je aktivní jen v případě, kdy v Typu dat je vybrána možnost: Podmínka. Více informací k této položce viz níže |
|


Při vyhodnocování výrazů a SQL dotazů lze využít dosazení hodnoty získané parsingem aktuální položky. Tato hodnota se ve výrazu vždy nahradí za konstantu %s. Ve výrazech a SQL výrazech lze využívat i proměnné dříve nadefinované v definici. Pomocí proměnných lze tedy ve výrazech využít i hodnoty z jiných položek, než je položka aktuální.
V rámci provádění parsování importního souboru je možné si zapamatovat položku jako proměnnou a její hodnotu později využít v rámci importu daného business objektu (BO) při dalším zpracovávání na jiném řádku. Hodnota proměnné je platná pouze v průběhu zpracovávání jednoho hlavičkového BO. Proměnná je v definici importu identifikována prefixem *VAR*. Hodnotu proměnné je možné využít pro vyplnění položky: Výchozí hodnota, v podmínce vyhodnocované pro řádek subkolekce, ve výrazu a v SQL výrazu. Při využití proměnné ve výrazu nebo podmínce je nutné ji vždy použít s prefixem *VAR* a ukončit sufixem *VAREND*.
Na tomto příkladu je demonstrováno využití proměnné *VAR*Store_ID definované na hlavičkovém business objektu a její následné využití na řádku BO (dosazení do položky „Výchozí hodnota“).
Konstanta „%s“ je využita např. pro získání ID skladové karty. Konstanta nabude hodnotu XML položky pro daný řádek (article_gtin[1]) z importního souboru a využije se pro vyhodnocení SQL dotazu.
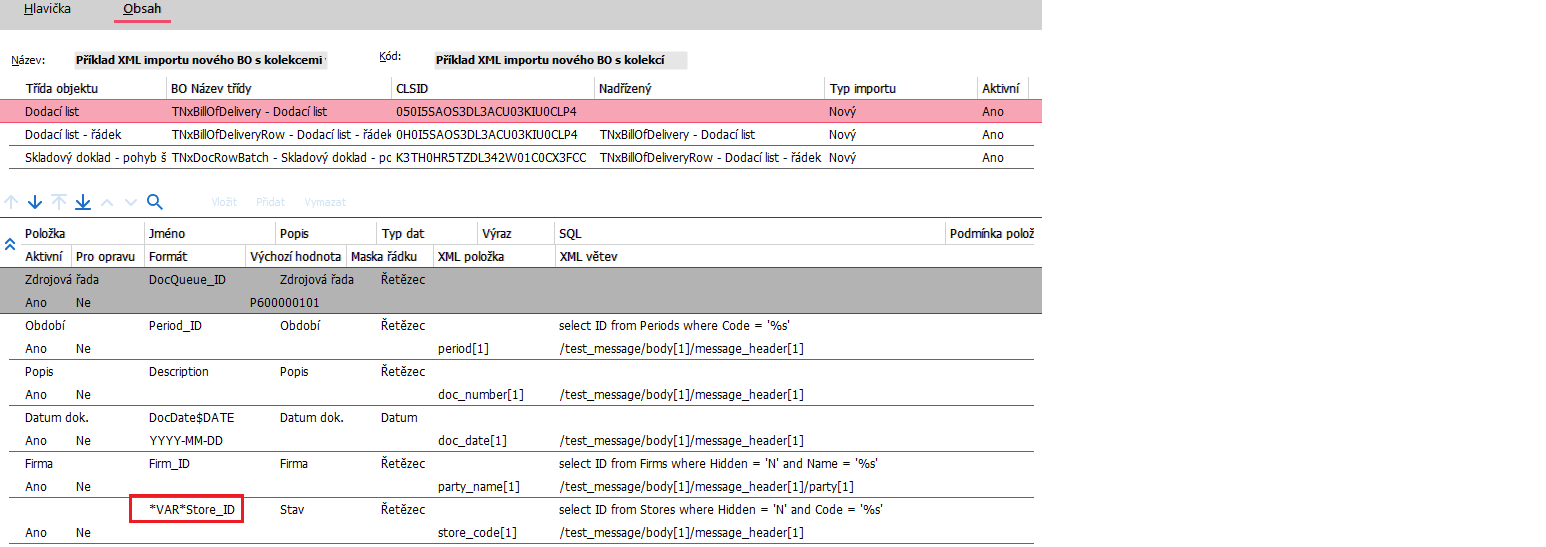
Na obrázku je vidět, že v poli Jméno je definovaná proměnná *VAR*Store_ID. Hodnota této proměnné se získává pomocí SQL dotazu vpravo.
Na tomto obrázku je vidět proměnná *VAR*Store_ID použita v poli Výchozí hodnota pro položku Sklad.
Tuto možnost nastavíme v položce Typ dat tehdy, pokud potřebujeme proměnnou nadefinovanou na kolekci BO použít také v subkolekci BO. V takovém případě je potřeba na kolekci nejprve nadefinovat to, že proměnnou budeme používat i v subkolekcích, tzn. nastavit proměnné Typ dat: Jedinečná přípona proměnné. Ta bude sloužit jako vazební prvek mezi kolekcí a subkolekcí. Dále je potřeba v obsahu kolekce uvést proměnnou ještě jednou a přiřadit jí hodnotu. Poté se v subkolekci již proměnná použije běžným způsobem popsaným v příkladu výše. Definici proměnné s jedinečnou příponou si popíšeme na příkladu.
V tomto příkladu potřebujeme naimportovat skladovou kartu,a to včetně jednotek, obalů a EANů. V importních datech (viz obrázek níže) máme několik řádků. Každý je definován maskou řádku.
Řádek s maskou SC obsahuje data o kódu a názvu skladové karty.
Řádek s maskou UNIT obsahuje informace o jednotce a množství.
Řádek s maskou CONT obsahuje informace k obalům. Je zde vazební jednotka a kód skladové karty obalu.
Řádek s maskou EAN obsahuje informace k EANům. Je zde vazební jednotka mezi EANem a jednotkou a EAN.
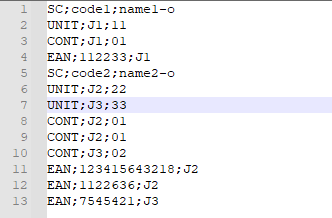
Datový zdroj obsahuje řádky s maskou řádku. Jednotlivé hodnoty v tomto importním souboru jsou popsány nad obrázkem.
Na jednotce skladové karty je na první pozici nadefinována proměnná s názvem *VAR*UnitQuantity a typem dat Jedinečná přípona proměnné. Tato proměnná se odkazuje na řádek s maskou UNIT a na pozici 2, Tím je definován konkrétní vazební prvek, který později použijeme v subkolekci. Důležité je zde především definovat proměnnou s jedinečnou příponou na první pozici před jejím naplněním daty.
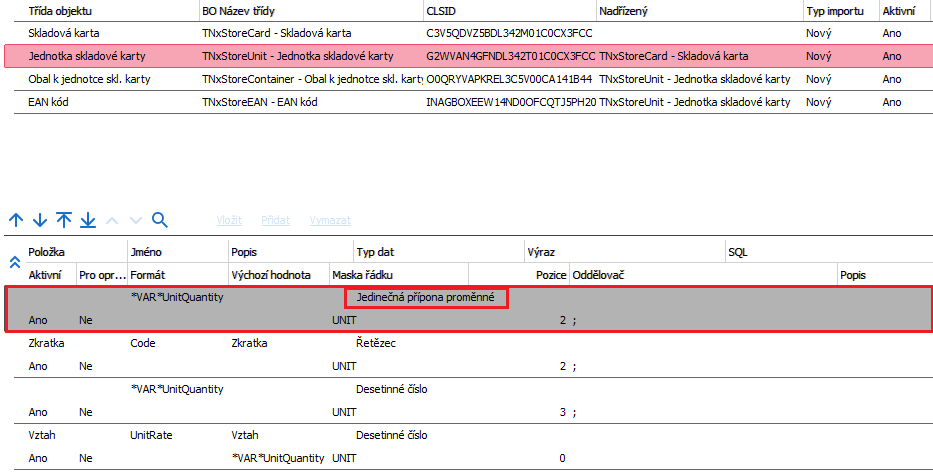
Na obrázku je vidět proměnná *VAR*UnitQuantity. Důležité je v položce Typ dat vybrat volbu Jedinečná přípona proměnné.
V dalším kroku zůstáváme stále na kolekci jednotky skladové karty, kde si do proměnné *VAR*UnitQuantity budeme načítat hodnotu. Opět z řádku s maskou UNIT, tentokrát z pozice 3.
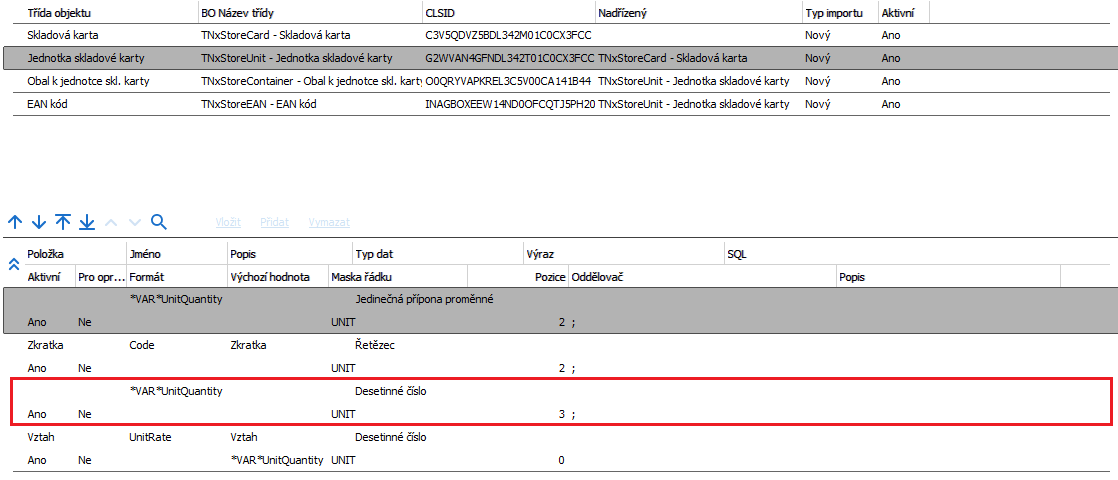
Na obrázku je vidět proměnná *VAR*UnitQuantity s typem dat Desetinné číslo, do které načítáme hodnoty z pozice 3, řádků označené maskou UNIT.
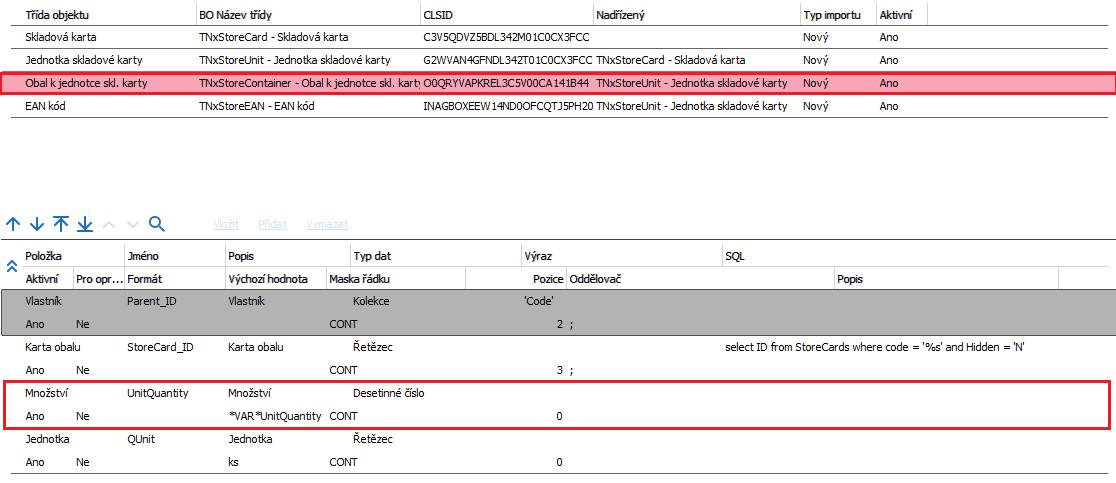
Další krok již ukazuje Subkolekci Obal k jednotce skladové karty. Zde je opět použita proměnná *VAR*UnitQuantity pro Množství. Díky prvnímu řádku s typem dat Kolekce, odkazem na řádek s maskou CONT a pozice 2 se napojí správné množství obalů ke správné jednotce.
Na každém Business objektu (hlavičkové, kolekce i subkolekce.), dále jen BO definovatelných importů lze definovat podmínku a to i kombinaci podmínek spojených logickými operátory. Logický operátor se použije pro spojení s předchozí hodnotou podmínky. Podmínka musí mít vždy hodnotu Ano/Ne vyhodnocovanou při zpracování podmínky parsingem (pokud je použito cokoliv jiného, je potřeba ověřit, jak se systém zachová - např. výsledek “True“ bude vyhodnocovat jako “A“, ale také integer bude vždy “A“). V podmínce lze použít proměnné definovatelných importů a výchozí hodnoty, tedy známé běžné možnosti.
Podmínka je platná vždy pouze pro příslušný BO definice definovatelného importu. Hodnota podmínka je vždy uložena v Interním XML na první pozici každého BO.
Plnění podmínky pomocí Výrazu a vyhodnocení podmínky
Podmínka je vždy definována jako Výraz a platí pro celý BO. Položka Výraz tedy nesmí být v případě použití datového typu Podmínka prázdná.
SQL je nepřístupné, protože nevrací logickou hodnotu. Pokud bude v poli SQL obsah zapsán, změnou typu dat na Podmínku dojde k jeho vymazání.
Při zpracovávání Interního XML při přípravě BO pro uložení je hodnota podmínky u každého BO načtena. Pokud je podmínka neplatná, BO se neuloží.
Použití funkce: Zastavit zpracování po nesplněné podmínce
Použitím této funkce dojde ke zrychlení zpracování importu, protože se nebudou parsovat následující "zbytečné" položky. Typickým příkladem použití podmínek je pro zamezení duplicitního ukládání již jednou uložených BO při opakovaném importu.
Uživatel, v případě výsledku vyhodnocení podmínky "Ne", má možnost proces parsingu při zpracování definovatelného importu zastavit. Uživatel si nastaví položku Zastavit zpracování po nesplněné podmínce na hodnotu: Ano. Takové nastavení dává smysl například pro jednu podmínku na objektu nebo pokud jsou 2 podmínky spojené pomocí operátoru AND (Pokud hned první vyhodnocení skončí jako “N“, tak rovnou zastavíme import po první podmínce, protože výsledek kombinace bude vždy “N“). Naopak, pokud máme 2 podmínky s operátorem OR, tak na první podmínce ještě import zastavit nechceme, teprve pokud bude kombinace podmínek vyhodnocena jako “N“, tj. zastavení importu nastavíme až na 2. podmínce.
Již existující položka s názvem Podmínka položky se týká pouze konkrétní položky - vyhodnocuje se buď před zpracováním nebo po zpracování položky.
Při sestavování BO pro uložení může neplatná podmínka různě ovlivnit i podřízené BO kolekcí, které mají jako svůj nadřízený objekt BO, který se nezpracovává kvůli neplatné podmínce. Neexistující hlavičkový BO kvůli neplatné podmínce logicky způsobí i neuložení všech svých podřízených objektů. Při zpracování Interního XML je s tímto počítáno.
Upravené logování
V mechanismu definovatelných importů bylo na různých místech upraveno i logování s ohledem na nové funkcionality. Z logu lze nyní vyčíst, jak byla podmínka BO vyhodnocena. V příkladu níže je situace, kdy se při parsování zjistilo, že podmínka BO pro řádek objednávky přijaté je vyhodnocena na "Ne". Nedojde tedy ani k uložení BO s informací o předchozí nesplněné podmínce.
Parsing: Objednávka přijatá - řádek:, BOFieldName "_BOCOND_05CPMINJW3DL342X01C0CX3FCC", Maska "", RawValue "2", ProcessedValue(BOCondition after combining with previous BOcondition value) "N", pořadí importu "2", XMLCollection X-Path "/orion_message/body[1]/line_items[1]/item[2]"
Save-BO: IE TNxIESaveBusinessObjects: Fill BO values finished OK. BO name: TNxReceivedOrderRow - Objednávka přijatá - řádek.
05.03.2024 14:21:42 614, Jaroslav Novák, reRuntimeExe: ---IE TNxIESaveBusinessObjects: BO will not be processed because the condition for no processing is set. BO name: TNxReceivedOrderRow - Objednávka přijatá - řádek. (log may belong to next BO)
Tato část kapitoly popisuje, jak se import chová v některých nestardarních situacích. Tato část kapitoly bude postupně doplňována.
Oprava záznamu, kdy jsou v datech stejné údaje
Může se stát, že někdy máme v datech stejné údaje, např. máme dvě duplicitní střediska, nebo dva, či více duplicitních záznamů ve skladových kartách. Abychom chování při importu správně pochopili, ukážeme si jej na příkladu. Příklad je ryze informačního charakteru, duplicity by být neměly, ale ABRA Gen duplicity povoluje.
Mějme vytvořených 5 středisek v agendě Střediska s Kódem 100 a Názvem střediska např. "Středisko Praha". Potřebujeme u všech pěti záznamů s Kódem 100 importem změnit Název středisek na "Středisko Brno" Použijeme klasickou definici s Typem importu Oprava nebo nový. V obsahu zadáme ID pro dohledání podle Kódu střediska a SQL dotaz na dohledání ID pro opravu. V importním souboru budeme mít jeden záznam s kódem 100 a střediskem Středisko Brno. Import proběhne a změní všech pět nalezených záznamů z původní hodnoty na novou.
Situaci, kdy bychom importem chtěli změnit všech 5 středisek a každé na jiný Název není možné tímto způsobem provést, jelikož by se všechna střediska změnila na Název střediska posledního řádku importu. Taková situace by musela být ošetřena individuálně za pomocí Podmínky položky.
V dolní části záložky je k dispozici lišta navigátoru: Lišta navigátoru je shodná pro horní i spodní seznam.
 VložitPřidatVymazat
VložitPřidatVymazat
Navigátor v subzáložce Obsah v této agendě.
Navigátor v této záložce obsahuje tlačítka:
- Pro pohyb kurzoru po řádcích (na začátek, předchozí řádek, další řádek, na konec) dokladu, změně jejich pořadí a hledání hodnoty v seznamu.
- Vložit - Pro vložení nového řádku před aktuální řádek (na němž stojí kurzor).
- Přidat - Pro přidání nového řádku na konec.
-
Vymazat - Pro vymazání aktuálního řádku, resp. označených, pokud je nějaký označen.
Panel definovatelných formulářů řádků
Ve spodní části subzáložky dále může být zobrazena oblast pro zobrazování a zadání položek prostřednictvím uživatelsky definovatelných formulářů. Je k dispozici pouze, je-li v menu Nastavení aktuálně zatržena volba pro zobrazení uživatelských formulářů řádků. Umožňuje vybírat si z nadefinovaných uživatelských vstupních formulářů pro Business objekty řádků dané agendy a zobrazovat a zadávat si skrz ně potom jednotlivé údaje.
Pravidla pro použití tohoto panelu jsou pro všechny agendy, ve kterých se může vyskytnout, společná a byla podrobně popsána v kap. Panel definovatelných formulářů.
Subzáložka je k dispozici pouze, je-li v menu Nastavení aktuálně zatržena volba pro zobrazení uživatelských formulářů. Umožňuje vybírat si z nadefinovaných uživatelských vstupních formulářů a zobrazovat a zadávat si skrz ně potom jednotlivé údaje.
Pravidla pro použití této záložky jsou pro všechny agendy, ve kterých se může vyskytnout, společná a byla podrobně popsána v kap. Záložka Formuláře - obecně.
Zobrazení seznamu v Detailu
V některé části této záložky může být zobrazen Seznam (Panel pro zobrazení seznamu na jiných záložkách), tedy záznamy ze záložky seznam (podrobněji viz Společné prvky v dokladových agendách - záložka Detail).
Zobrazení seznamu závisí na aktuálním nastavení v menu Nastavení pro danou agendu a přihlášeného uživatele.
Funkce k záložce Detail:
Podmnožina funkcí ze záložky Seznam.
V editačním režimu platí zásady platné pro editaci záznamů v knihách. K dispozici jsou standardní funkce pro režim editace, přičemž po uložení záznamu v závislosti na jeho údajích může dojít k vyvolání nějaké další automatické akce, viz akce volané po uložení záznamu.
Další obsažené funkce:
| Název | Kl. | Doplňující popis: |
|---|---|---|
| Průvodce | - |
Umožňuje vyvolat průvodce, který ve dvou krocích provede naplnění BO a jejich subkolekcí. Podrobný popis Průvodce a jeho použití najdete v kapitole Věcný obsah - obecné. |
| Načíst definici |
- |
Funkce jejíž podrobný popis naleznete v popisu stejnojmenné položky na záložce Seznam. |
| Uložit definici | - |
Funkce jejíž podrobný popis naleznete v popisu stejnojmenné položky na záložce Seznam. |